By Alexander Serechenko, LLM Team Lead, Senior Developer & Platform Engineer at OneTick
This post is an overview of the architecture where we put together an MLOps framework that supports a multiple-user research environment, experiment tracking and evaluating system, parallel hyper-parameter tuning, and GPU/CPU/custom workers. Images are taken from the original article linked here.
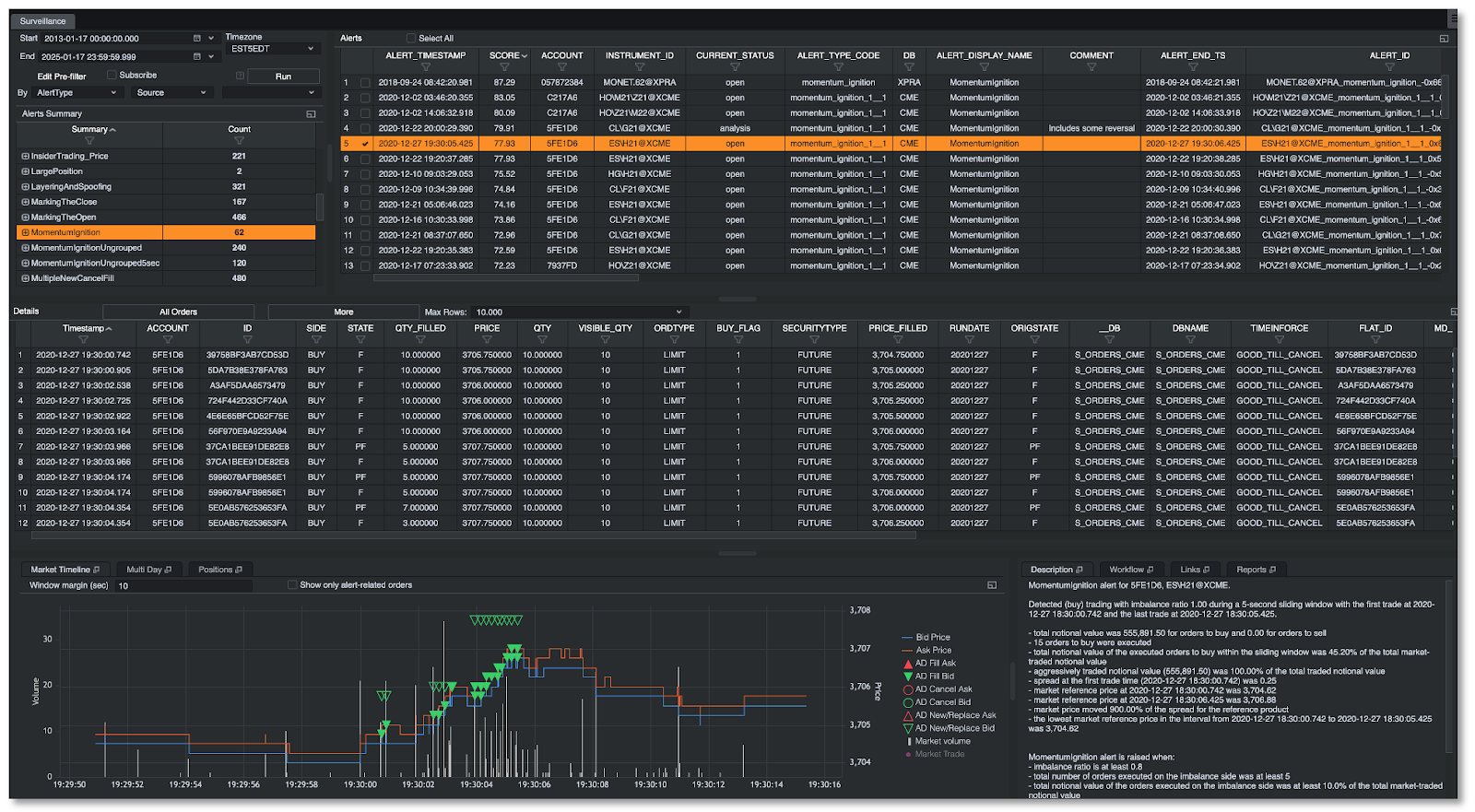
OneTick is a company specializing in time-series data storage, processing, and querying, and we are consistently developing machine-learning solutions for our clients. The specifics of the data we work on and the use cases we encountered motivated us to develop a practical workflow.
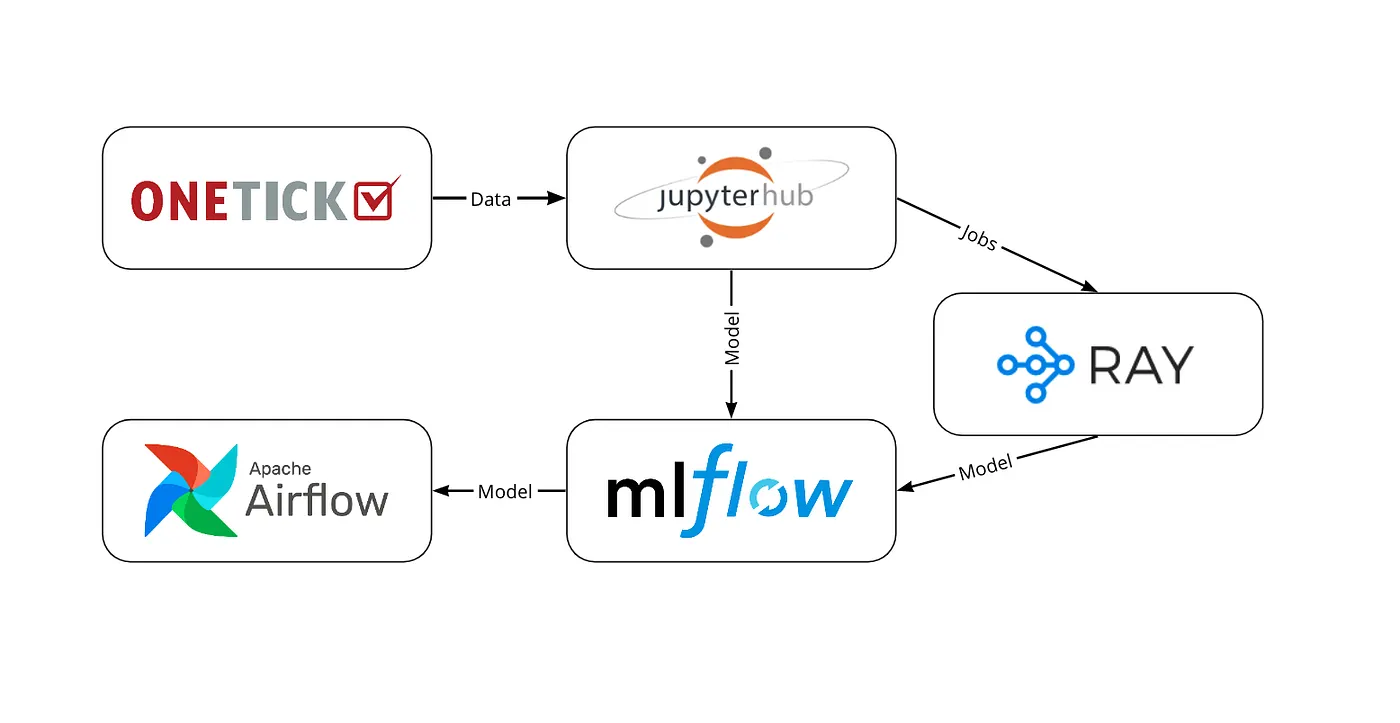
High-level architecture
Example case
To exemplify MLOps capabilities we picked a sample task of predicting next day’s trading volume and posting it on Twitter. In this example, we illustrate all steps from data analysis and model development to the final deployment with scheduled posting and re-training.
Research environment
First, we provide a unified multi-user environment based on JupyterHub. Each user has a dedicated JupyterLab instance, isolated from other users, and configurable with desired packages or libraries. Computing resources and isolation are controlled and managed by Docker.
Users research and develop different approaches for data preparation and model training like the one described in this article.
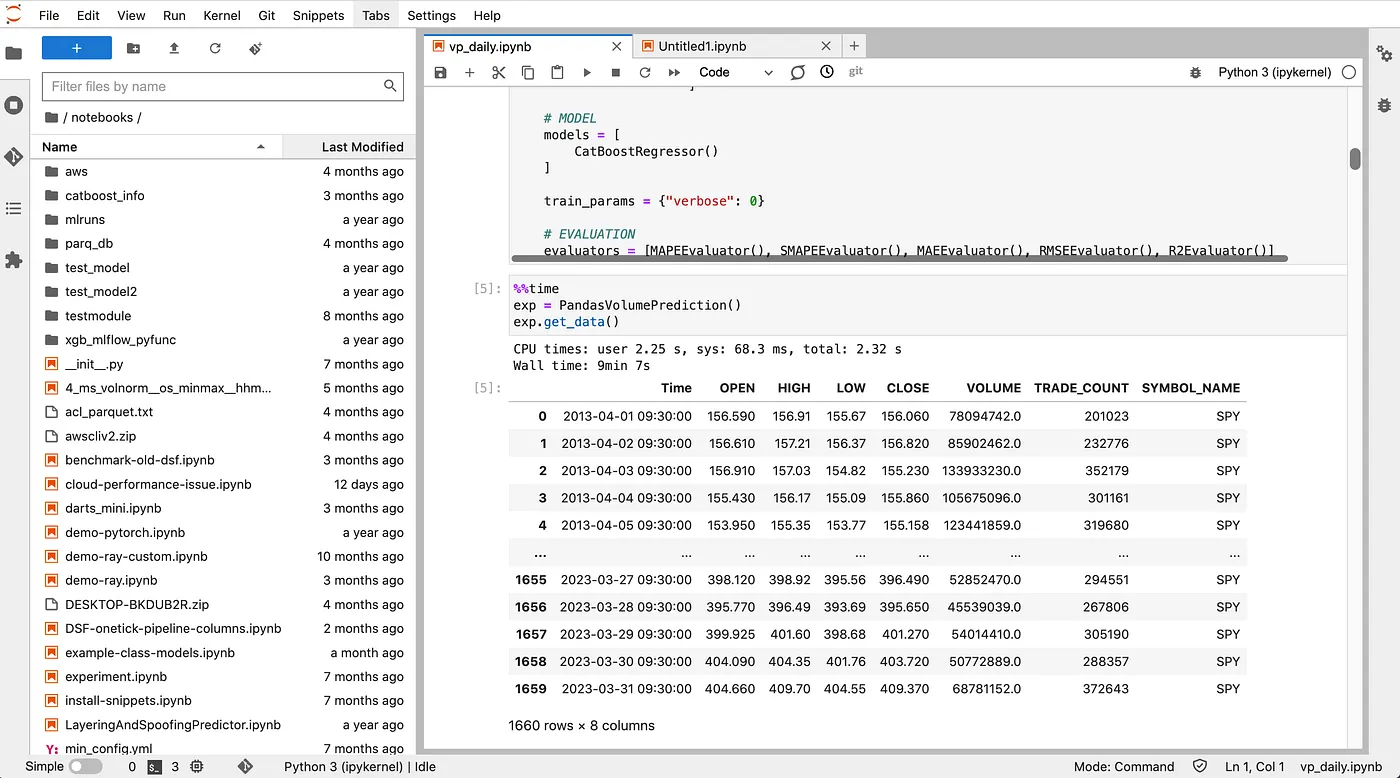
Research environment: JupyterLab UI
Data science framework
To deal with the specifics of time-series data in machine learning we developed a specialized Data Science Framework — a Python package that helps data scientists manage time-series experiments. In one common pipeline, users can define configurations for data loaders, feature extraction, preprocessing routines, splitting, model training, hyper-parameter optimization, cross-validation, early stopping, and final metrics evaluation. Each combination of these configurations constitutes an experiment, that is running a full cycle under the hood, producing a trained model with all necessary artifacts. This common pipeline gives an obvious and integral way to flexibly tune the parameters of any stage described above, in order to achieve the best resulting metrics.
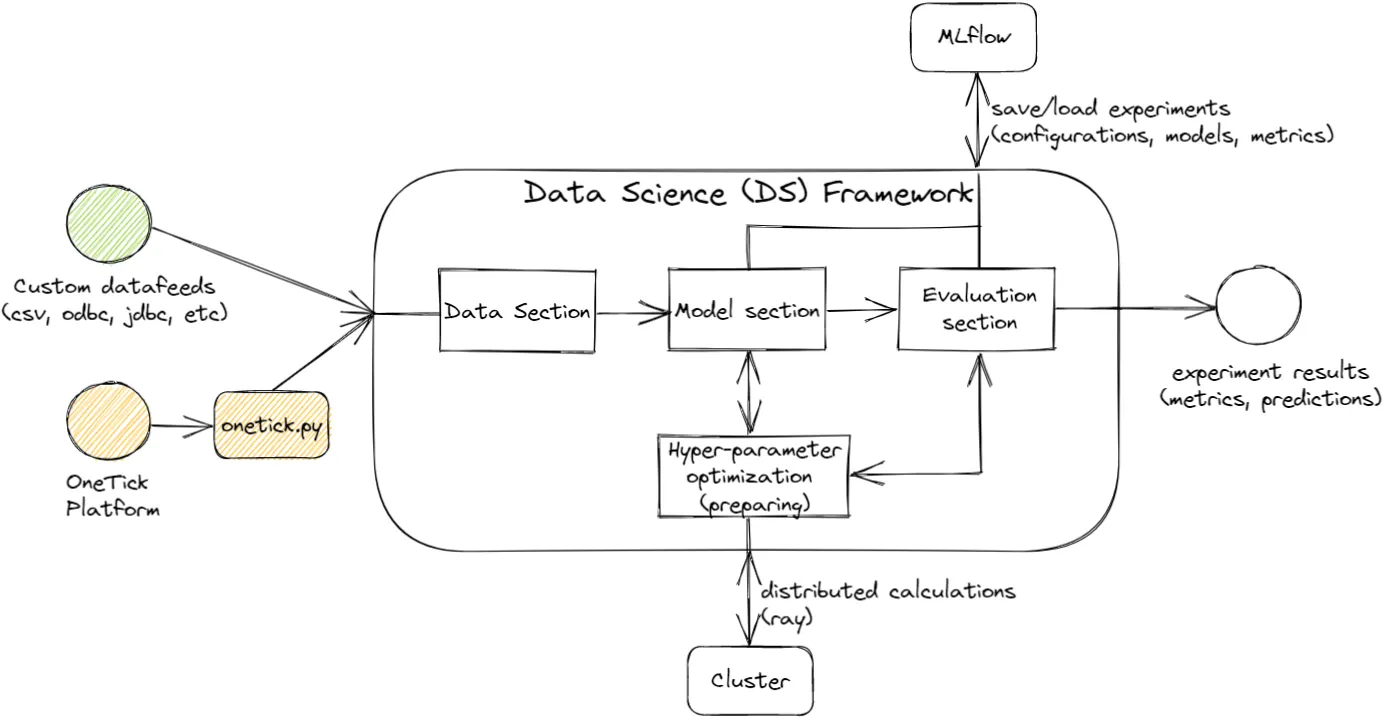
Extraction of features from market data is done efficiently in OneTick. Data pipelines are written in OneTick Python API, which mimics popular Pandas syntax.
Model development
Data Science Framework provides an integrated and simple way to start using different models based on popular libraries: SKLearn, PyTorch, Keras, XGBoost, CatBoost, LightGBM, etc. All models utilize a common SKLearn interface, which is considered an industry standard, and used to handle hyper-parameter tuning as well as data folding and final re-training. Also, this interface allows users to define custom models, keeping the ability to use cross-validation and grid search with these models as well.
Experiment tracking
All configurations and results are tracked and saved for comparison later. Tracked runs in fact give the ability to reproduce any experiment or load selected models for deployment in the future. We use MLFlow as a model registry and experiment tracking server, and this is covered by the Data Science Framework and Research Environment is preconfigured for this out-of-box.
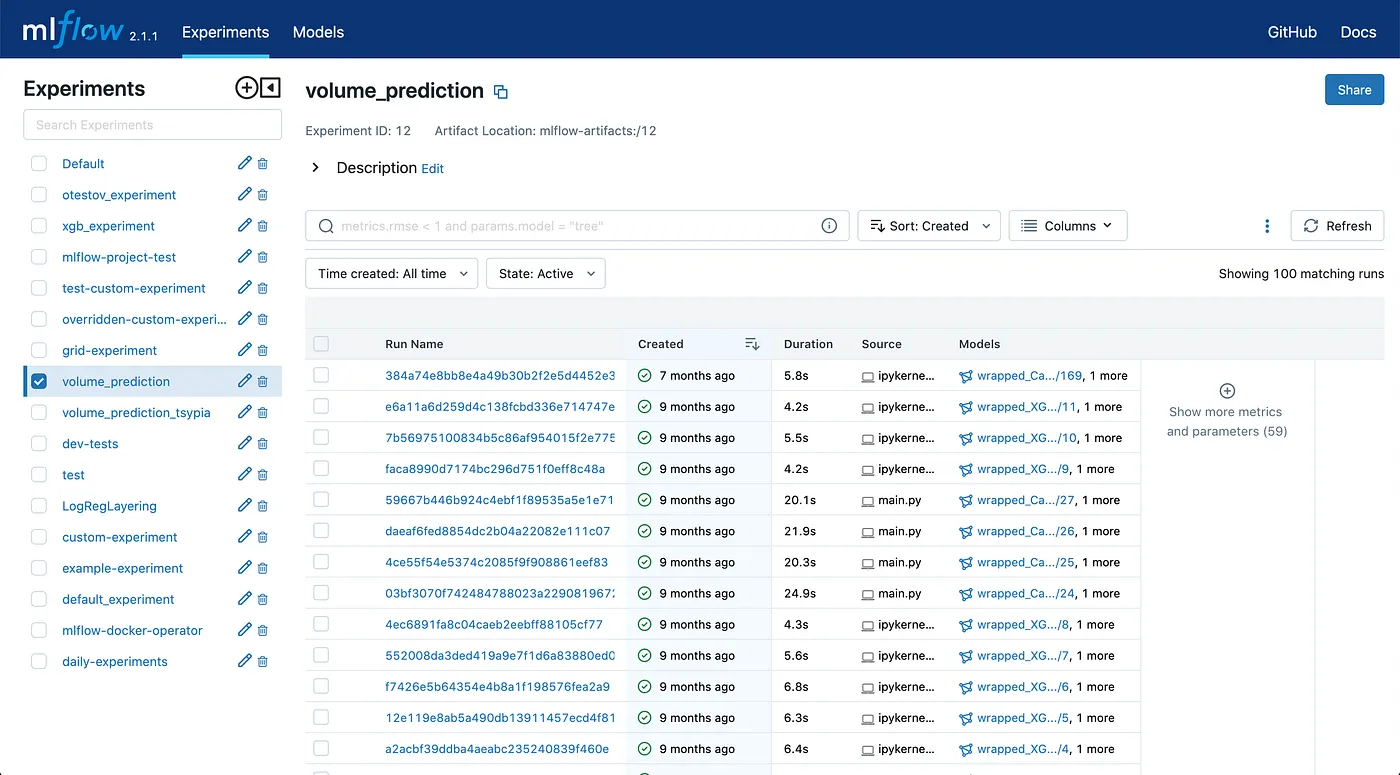
MLFlow UI
Parallelization
Hyper-parameter tuning with a grid search, as well as cross-validation, are popular ML methods of model development. Both require models to be trained multiple times with small changes in configuration. Data Science Framework provides a simple mechanism to manage this parallelization on the Ray Cluster.
Ray is a distributed computing framework oriented on ML/DS cases. It is easy to bootstrap on AWS, on GCP, or on a custom Kubernetes cluster, and it uses these platforms’ APIs to upscale and downscale on demand, preserving us from unexpected expenses.
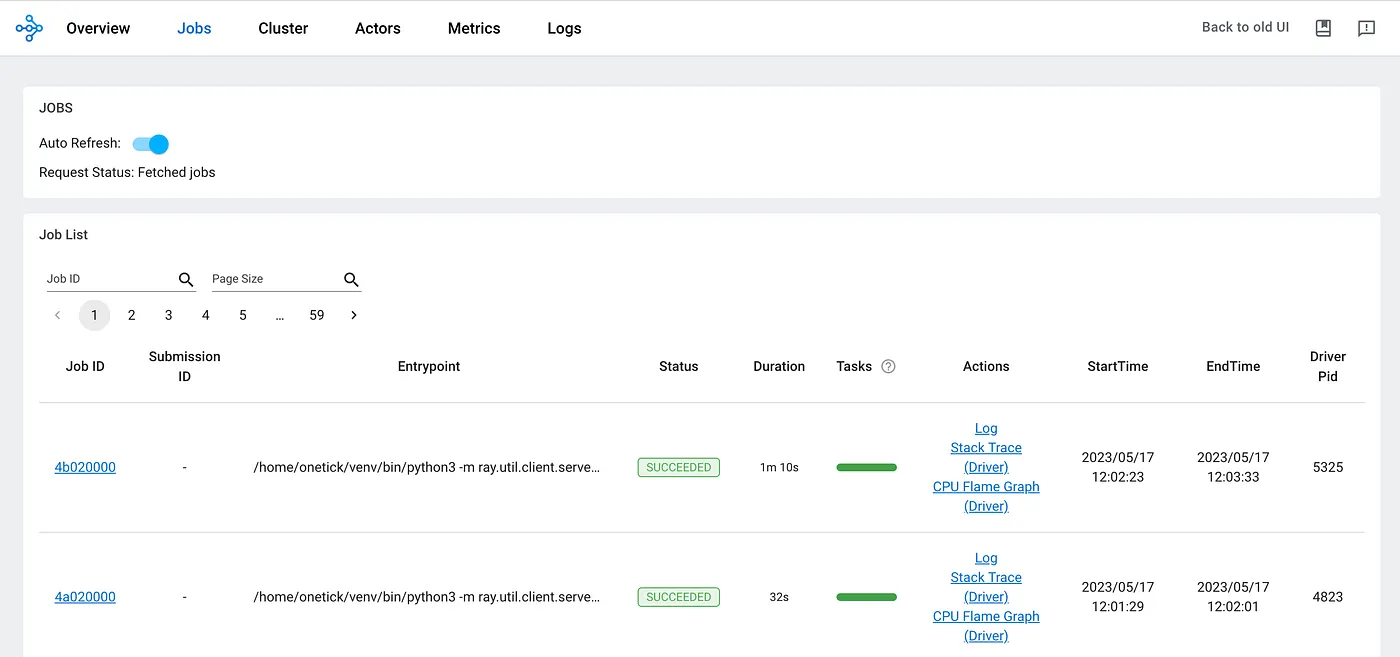
Ray dashboard UI
Model serving and re-training
After experiments are finished and data scientists produced an ML model with appropriate metrics, we schedule everyday predictions for a next-day volume. We use Airflow software to automate prediction running and posting results to Twitter in a simple DAG (Directed Acyclic Graph) with these two tasks. Airflow worker runs a docker container and builds an isolated model-specific environment inside, with all requirements tracked and preserved by MLFlow. A special sensor triggers the DAG to run only after all required data about the last trading day has arrived in the database.

Post from our Volume Prediction Bot
Monitoring accuracy
To monitor the model, which can outdate and predict less accurately over a long period of time, we built another DAG with the model re-training process. Data Science Framework wraps native ML models with a Pythonic interface with the whole data loading and preprocessing pipeline saved in MLFlow, making it easy to replicate the training process.
After re-training is finished, metrics are compared with metrics of the current model, and if the new model is performing better, we receive a Slack notification and update the MLFlow model identifying in an Airflow configuration for prediction DAG.
Conclusion
Described MLOps architecture could be adopted for a wide range of market data cases, such as but not limited to:
- Searching for trading anomalies in Surveillance
- Market predictions for Transaction Cost Analysis
- Tickers clustering
Want to learn more? Feel free to contact us at ml@onetick.com or submit a demo request form to set up a meeting with our data experts today.
Best wishes,
Alexander Serechenko, LLM Team Lead at OneTick